Webarchive - веб-архів всього інтернету і сайтів або машина часу на archive.org
- Як можна використовувати архів сайтів інтернету
- Відкриття мертвих посилань і умови потрапляння сайту в archive.org
- Як знайти потрібний веб-архів і відновити сайт без бекапа
- Як витягнути з Webarchive унікальний контент для сайту
Привіт, шановні читачі блогу KtoNaNovenkogo.ru. Не так давно я писав про те, що таке народна енциклопедія Вікіпедія , Яка безумовно заслуговує всяких приємних епітетів, незважаючи на властиві їй невеликі недоліки і критику її статей з боку наукового співтовариства.
Сам факт того, що некомерційний проект вже не одне десятиліття працює на благо всього інтернет спільноти, заслуговує на величезну повагу. Але в мережі є ще подібний масштабний проект, який не отримуючи з цього доходу виконує дуже важливу роль - зберігає архіви сайтів, відео, аудіо та друкованої продукції.
Я кажу, звичайно ж, про web.archive.org - глобальний проект з здавалося б нездійсненною місією - створення архіву всіх сайтів, коли або розміщених в інтернеті. Причому, сайти зберігаються не у вигляді скріншотів, а у вигляді повноцінно працюють веб-сторінок з усіма посиланнями, картинками і стильовим оформленням (CSS) . Причому, для кожного сайту за час його існування в мережі в цьому архіві може накопичитися і по кілька сотень копій, датованих різними етапами життя ресурсу.
Як можна використовувати архів сайтів інтернету
Чим же може бути корисний даний webarchive?
- Ну, по-перше, ви можете зануритися в приємну ностальгію подорожуючи по вашому сайту багаторічної давності. Простежити історію змін можна буде для будь-якого іншого ресурсу інтернету (наприклад, я брав скріншоти для статей про вже померлий Апарат саме з це вебархіва, та й скріншоти, що ілюструють еволюцію головної сторінки Яндекса , Мають те ж саме походження).
- Але це не все. Якщо сторінка доданого вами в закладки сайту не відкривається, то ви, звичайно ж, можете спробувати витягти її з кеша Яндекса або Гугла (читайте докладніше про те, як краще шукати в Google ). Але якщо ресурс недоступний вже дуже давно, то такі мертві посилання ніде крім archive.org відкрити вже буде не можливо (правда, і там його може не виявитися за описаними трохи нижче причин).
- Так само, якщо ви з якихось форс-мажорних обставини не робили бекап (резервне копіювання) вашого сайту , То даний web archive буде єдиною можливістю відновити свій сайт. Є можливість очистити всі посилання від прив'язки до web.archive.org і зробити їх прямими саме для вашого ресурсу (читайте про це нижче).
Ну, і останнє, що приходить в голову - пошук унікального контенту. Якщо ви не здатні самі створювати унікальний контенту для сайту (писати статті), то тут ви зможете ними розжитися, правда, зусилля докласти все одно доведеться. Суть така, що багато сайтів вмирають і стають недоступні разом з наявними на них контентом.
Відшукавши такі ресурси ви зможете витягнути тексти з Інтернет-архіву і розмістити їх у себе, попередньо перевіривши їх на унікальність . Таким чином ви не займаєтеся плагіатом і не порушуєте авторські права (копірайт) , Але шукати в вебархіве багатьом може здатися дуже вже трудомістким завданням.
Онлайн сервіс Webarchive веде свою історію аж з 1996 року. Поставлена перед проектом завдання здавалася нездійсненною навіть з урахуванням того, що сайтів на той час в інтернеті було значно менше, ніж зараз (на кілька порядків). По початку, сайти архівувалися не дуже часто, але з часом, підвищуючи потужності сховищ, Веб-архів став робити все більше і більше зліпків сайтів.
Сам себе цей веб архів заніс в базу лише в 1997 році і виглядала його головна сторінка тоді так:
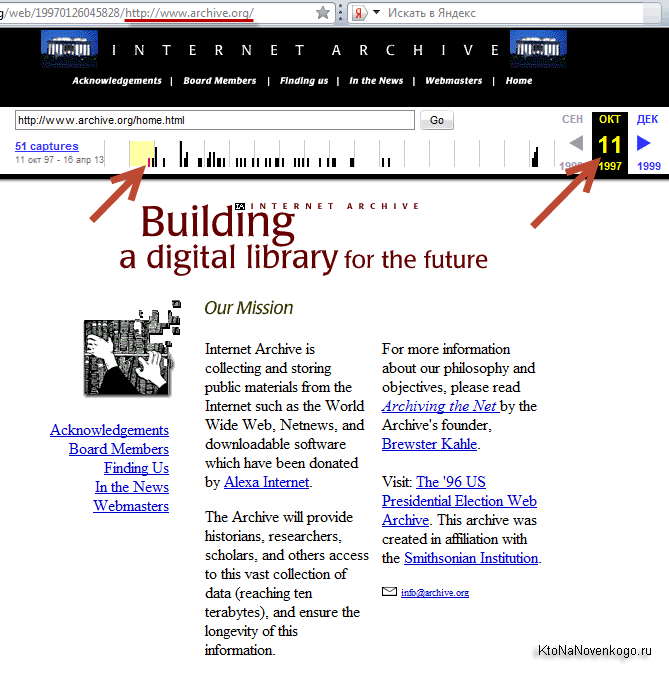
Зараз на все про все (включаючи аудіо, відео та відскановані книги) у цієї некомерційної організації задіяно дисковий простір жахливих розмірів, що вимірюється десяткою з п'ятнадцятьма нулями байт. Сайт має дзеркала в різних дата центрах, а сам проект з недавніх пір отримав офіційний статус бібліотеки. Якщо розглядати тільки архів сторінок сайтів, то їх вже там налічується близько ста мільярдів (тут враховуються всі зліпки сторінок коли-небудь зняті і збережені).
на головній сторінці доступний не тільки архів сторінок інтернету Wayback Machine, але і архіви різних кінохроніки, телепередач, аудіо записів і відсканованих в різних бібліотеках книг:
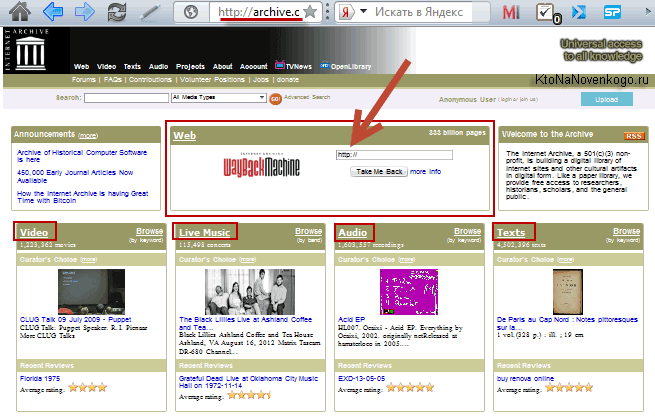
Але нас цікавить саме область WEB з логотипом Wayback Machine . В розташовану там форму можна ввести URL або доменне ім'я цікавить вас сайту (читайте про те, що таке домен і чим він відрізняється від URL ), Щоб потрапити на сторінку з календарем:
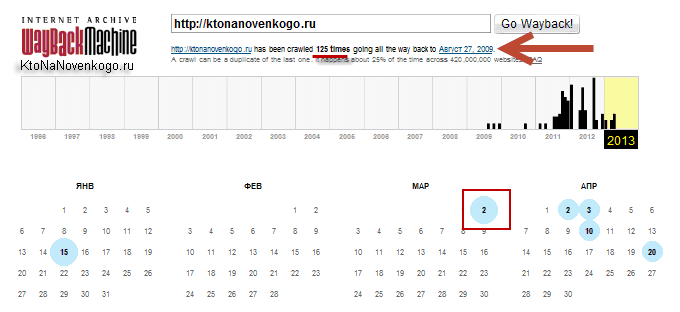
З наведеного прикладу видно, що мій блог був вперше архівувати 27 серпня 2009 року (через п'ять днів після реєстрації (купівлі) домену ktonanovenkogo.ru). За минулий інтервал часу було створено 125 архівних копій сайту, кожну з яких можна буде побачити і помацати руками (здійснюючи переходи по внутрішнім посиланням).
Відкриття мертвих посилань і умови потрапляння сайту в archive.org
У календарі блакитними кружечками відзначені дати, в які був створений зліпок (вебархів) даного сайту. Природно, що моменти зняття зліпка не стане коррелироваться з виробленими на вашому ресурсі змінами, і їх час Webarchive визначає строго виходячи зі своїх внутрішніх алгоритмів і таймерів.
Тому використовувати архів інтернету, як інструмент для відкриття тимчасово недоступних сайтів, напевно, не завжди буде резонним. Для цього у Яндекса є можливість перегляду архівної копії документа:

Так, і в Google можна завжди подивитися збережену копію веб-сторінки:

Даний же онлайн сервіс знадобиться в особливо важких випадках, коли шукана сторінка вже не існує і навряд чи вже буде існувати в реальному інтернеті, але зате вона як і раніше буде доступна в машині часу.
Правда, тут має бути дотримано кілька умов того, щоб сайт потрапив в archive.org:
Він не повинен містити в своєму файлі robots.txt заборона для його індексації роботом з web.archive.org. Така заборона, зазвичай виглядає так:
User-agent: ia_archiver Disallow: /
Коли я писав статтю про електронну пошту mail.ru , То не зміг знайти в Архіві Інтернету збережених копій сайту mail.ru, тому що його файл robots.txt містив в собі схожий заборона:

- Деякі сайти Вебархів з яких-небудь причин банально не знайшов. Ймовірність влучення ресурсу в базу підвищується, якщо він буде доданий в каталог Dmoz або ж якщо на нього будуть проставлені посилання з інших популярних ресурсів, які в Webarchive вже знаходяться. Загалом то, навіть простий запит через форму на головній сторінці цього сервісу може послужити поштовхом до залучення уваги цього архіватора до вашого ресурсу.
Як знайти потрібний веб-архів і відновити сайт без бекапа
По архівах можна переміщатися і за допомогою тимчасової шкали розташованої у верхній частині сторінки, де вертикальними чорними рисками відзначені наявні для цього сайту зліпки. Іноді, веб-архіви можуть бути битими, тоді доведеться відкрити найближчий до нього зліпок.
Натиснувши на блакитному кружечку ми можемо побачити посилання на кілька архівів, що відрізняються часом їх зняття.
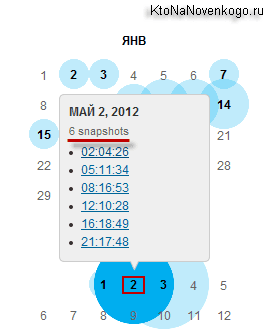
Можливо, що це робиться, щоб запобігти втрату даних за рахунок неминучої псування жорстких дисків в сховищах. Перейшовши до перегляду одного з веб-архівів, ви побачите копію свого (в даному прикладі мого) сайту з працюючими внутрішніми посиланнями і підключеним стильовим оформленням. Правда, не ідеально працюють.
Наприклад, дещо з дизайну у мене все ж перекосило і бічне меню працює на ДжаваСкрипт повністю зникло:
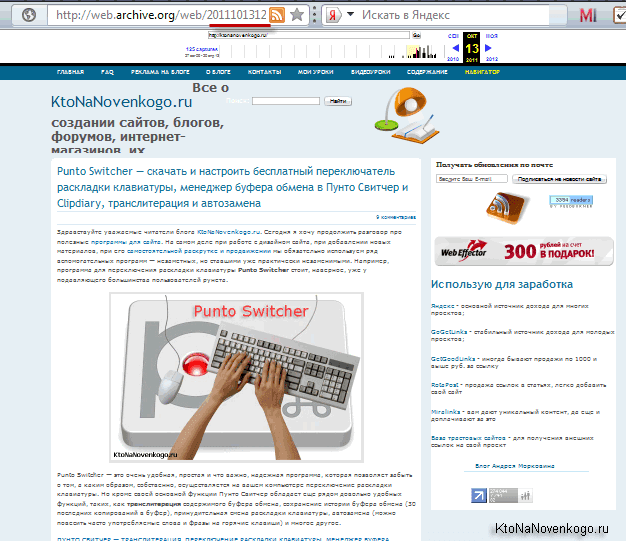
Але це не настільки важливо, бо в вихідному коді сторінки з web.archive.org це меню, природно, присутній. Однак, просто так скопіювати текст цієї сторінки до себе на сайт замість втраченої не вийде. Чому? Та тому що подорож всередині сайту з минулого буде можливо лише в разі заміни всіх внутрішніх посилань на ті, що генерує Webarchive (в іншому випадку вас перекинуло б на сучасну версію ресурсу).
Виглядають ці посилання приблизно так:
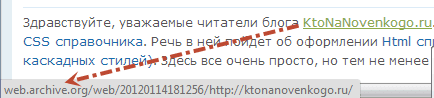
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/seo/search/samostoyatelnoe-prodvizhenie-sajta-kak-prodvigat-samomu-vnutrennej-optimizaciej.html
Зрозуміло, що можна буде вручну відсікти вступну частину посилань (http://web.archive.org/web/20111013120145/), отримавши таким чином робочий варіант. Можна цей процес навіть автоматизувати за допомогою інструменту пошуку і заміни редактора Notepad , Але ще простіше буде скористатися вбудованою в цей сервіс можливістю заміни внутрішніх посилань на оригінальні.
Для цього копіюєте адресу сторінки з потрібним зліпком вашого сайту (з адресного рядка браузера - починається з http://web.archive.org/). Він буде мати приблизно такий вигляд:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/
І вставляєте в нього конструкцію «id_» в кінці дати (20111013120145), щоб вийшло так:
http://web.archive.org/web/20111013120145id_/https://ktonanovenkogo.ru/
Тепер змінений адреса назад повертаєте в адресний рядок браузера і тиснете на Enter. Після цього сторінка c архівом вашого сайту оновиться і всі внутрішні посилання стануть прямими. Можна буде копіювати текст статті з вихідного коду вебархіва.
Зрозуміло, що відновлення таким чином величезного сайту займе жахливу кількість часу, але коли іншого варіанту немає, то і такий здасться манною небесною. До того ж, страждають безповоротної втратою контенту зазвичай тільки початківці вебмастера, у яких цього самого контенту було мало, а більш-менш досвідчені сайтовладельцев, вже не раз обпікалися на подібних речах, роблять бекапи файлів і бази по п'ять разів на дню.
Якщо ви захочете побачити всі сторінки вашого (або чужого) сайту, які містяться в надрах цього мастодонта, то вам потрібно буде вставити в адресний рядок браузера наступну адресу і натиснути Enter:
http://wayback.archive.org/web/*/ktonanovenkogo.ru*
Замість мого імені можна використати свій. На сторінці, ви отримаєте можливість накласти фільтр в призначеної для цього формі:
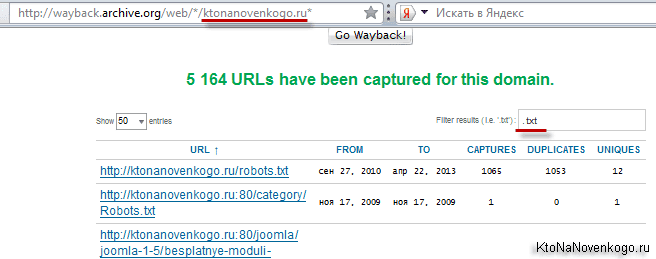
Наприклад, я захотів побачити лише текстові файли свого блогу, які заковтнула Web Archive. Навіщо - не знаю, але захотів.
Як витягнути з Webarchive унікальний контент для сайту
Описаний нижче спосіб особисто я не використовував, але чисто теоретично все має працювати. Саму ідею я почерпнув на цьому молодому ресурсі, де і були описані всі кроки. Принцип методу полягає в тому, що кожен день вмирають і ніколи не відроджуються десятки сайтів.
Причин цьому може бути багато і більшість з покійних в бозі ресурсів ніякої особливої цінності в плані контенту ніколи і не представляли. Але з будь-якого правила бувають винятки і потрібно буде всього-на-всього відокремити зерна від плевел. Головне щоб зниклі сайти з більш-менш легкотравним контентом були б представлені в Web Archive, хоча б однією копією.
Оскільки після смерті контент цих сайтів поступово випаде з індексу пошукових систем, то взявши його з інтернет-архіву ви, по ідеї, станете його законним власником і першоджерелом для пошукових систем. Чудово, якщо буде саме так (є варіант, що ще за життя ресурсу його нещадно могли откопіпастіть). Але крім проблеми унікальності текстів, існує проблема їх відшукання.
По-перше, нам потрібен список сайтів, які скоро помруть або вже померли. Автор методу пропонує завантажити з сайту реєстратора доменних імен Nic.ru список звільняються або вже звільнилися доменів .
Що примітно, в останній колонці цього списку (його можна відкрити в Excel) буде відображатися кількість архівів, створених для кожного сайту в Web Archive (правда, перевірити наявність домену в веб-архіві можна і в ряді онлайн сервісів, наприклад, на цьому або на цьому ).
Список буржуйських доменних імен, що звільняються або вже звільнилися, пропонується завантажити по цьому посиланню . Ну, а далі переглядаємо вміст сайтів, яке зберіг Web Archive і намагаємося знайти щось вартісне. Потім перевіряємо унікальність цих матеріалів (посилання приводив трохи вище) і в разі успіху публікуємо їх на своєму ресурсі, або продаємо в який-небудь біржі контенту .
Так, спосіб тоскний і мною особисто не перевірений. Але, думаю, що при деякій мірі автоматизації і обмозговиванія він може давати непоганий вихлоп. Напевно, хтось уже це поставив на потік. А ви як думаєте?
Удачі вам! До швидких зустрічей на сторінках блогу KtoNaNovenkogo.ru
Збірки по темі
Використовую для заробітку
Чому?А ви як думаєте?