Пошук шляхів в графі | AlterVision | Антон AlterVision Резниченко
- алгоритм Флойда
- опис алгоритму
- псевдокод
- складність алгоритму
- Побудова матриці досяжності
- алгоритм Йена
- суть алгоритму
- Модифікація алгоритму Йена
- Реалізація
- клас array
- Клас floyd і реалізація алгоритму
- Вирішувач - функція floyd
- Демонстрація роботи алгоритму
- Висновок
- ПОСИЛАННЯ
- Автор
Завдання знаходження найкоротшого шляху є, мабуть, найбільш важливим завданням теорії графів. Існує безліч алгоритмів пошуку як найкоротших, оптимальних шляхів, так і субоптимальних шляхів. Субоптимальних шляхом будемо називати шлях, що веде з початкової до кінцевої точки, але відрізняється від оптимального шляху. Сенс знаходження субоптимальних шляхів легко розглянути на такому прикладі: припустимо, що завдання пошуку шляху безпосередньо описує наш шлях по місту. В такому випадку оптимальний шлях в залежності від часу може виявитися неможливим до реалізації (наприклад, одна з гілок дороги перегороджена пробкою через аварію). В такому випадку нас буде цікавити субоптимальний шлях, або по-іншому, об'їзд.
Рішення завдання пошуку оптимального шляху ми проведемо за алгоритмом Флойда, субоптимальних шляху знайдемо за алгоритмом Ієна.
алгоритм Флойда
Алгоритм Флойда - Воршелла - динамічний алгоритм для знаходження найкоротших відстаней між усіма вершинами зваженого орієнтованого графа. Розроблено в 1962 році Робертом Флойдом і Стівеном Уоршеллом
опис алгоритму
Нехай вершини графа 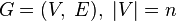 пронумеровані від 1 до n і введено позначення
пронумеровані від 1 до n і введено позначення 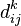 для довжини найкоротшого шляху від i до j, який крім самих вершин
для довжини найкоротшого шляху від i до j, який крім самих вершин 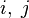 проходить тільки через вершини
проходить тільки через вершини 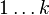 . Очевидно, що
. Очевидно, що 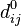 - довжина (вага) ребра
- довжина (вага) ребра 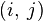 , Якщо таке існує (в іншому випадку його довжина може бути позначена як
, Якщо таке існує (в іншому випадку його довжина може бути позначена як 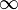 )
)
Існує два варіанти значення 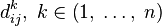 :
:
- Найкоротший шлях між не проходить через вершину k, тоді
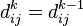
- Існує більш короткий шлях між , Що проходить через k, тоді він спочатку йде від i до k, а потім від k до j. У цьому випадку, очевидно,
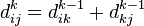
Таким чином, для знаходження значення функції досить вибрати мінімум з двох позначених значень.
Тоді рекуррентная формула для 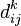 має вигляд:
має вигляд:
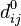 - довжина ребра
- довжина ребра
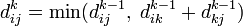
Алгоритм Флойда - Воршелла послідовно обчислює всі значення , 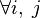 для k від 1 до n. отримані значення
для k від 1 до n. отримані значення 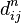 є довжинами найкоротших шляхів між вершинами .
є довжинами найкоротших шляхів між вершинами .
псевдокод
На кожному кроці алгоритм генерує двовимірну матрицю W, 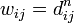 . Матриця W містить довжини найкоротших шляхів між усіма вершинами графа. Перед роботою алгоритму матриця W заповнюється довжинами ребер графа.
. Матриця W містить довжини найкоротших шляхів між усіма вершинами графа. Перед роботою алгоритму матриця W заповнюється довжинами ребер графа.
for
k = 1 to n for i = 1 to n for j = 1 to n W [i] [j] = min (W [i] [j], W [i] [k] + W [k] [j ])
складність алгоритму
Три вкладених циклу містять операцію, виконувану за константне час. 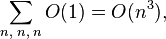 тобто алгоритм має кубічну складність, при цьому простим розширенням можна отримати також інформацію про найкоротших шляхах - крім відстані між двома вузлами записувати матрицю ідентифікатор першого вузла в дорозі.
тобто алгоритм має кубічну складність, при цьому простим розширенням можна отримати також інформацію про найкоротших шляхах - крім відстані між двома вузлами записувати матрицю ідентифікатор першого вузла в дорозі.
Побудова матриці досяжності
Алгоритм Флойда - Воршелла може бути використаний для знаходження замикання відносини E по транзитивності. Для цього в якості W [0] використовується бінарна матриця суміжності графа, 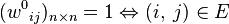 ; оператор min замінюється диз'юнкція, складання замінюється кон'юнкція:
; оператор min замінюється диз'юнкція, складання замінюється кон'юнкція:
for
k = 1 to n for i = 1 to n for j = 1 to n W [i] [j] = W [i] [j] or (W [i] [k] and W [k] [j] )
Після виконання алгоритму матриця W є матрицею досяжності.
алгоритм Йена
Знаходження k найкоротших шляхів в графі
Є неорієнтований граф. Складається з вершин і ребер, ребрах приписані довжини. Вершин кілька тисяч (N штук), кількість ребер відомо (M штук). Додаткових відомостей про співвідношення числа ребер і числа вершин немає.
Треба знайти кілька найкоротших шляхів без циклів між двома заданими точками (K штук шляхів, K задається, K порядку декількох десятків)
суть алгоритму
Дозволяє знаходити k-найкоротші шляхи без циклів послідовно.
Цей алгоритм передбачає, що ми вміємо знаходити один найкоротший шлях в графі.
Робиться це так: Будемо вести список кандидатів в найкоротші шляхи. Знаходиться перший найкоротший шлях. Так як всі інші шляхи не повинні збігатися з першим шляхом, то ці інші шляхи не містять як мінімум одне з ребер першого шляху. Тому, викидаємо по одному ребру з першого шляху і знаходимо найкоротші шляхи в одержуваних графах. Знайдені шляхи (з позначкою про те, яке ребро було викинуто) додаємо в список кандидатів. Зі списку кандидатів вибираємо найкоротший шлях - це другий найкоротший шлях.
Далі знаходимо наступний найкоротший шлях аналогічно. При знаходженні кожного найкоротшого шляху в список кандидатів додається не більше N нових шляхів (насправді звичайно менше).
При видаленні ребра знаходження найкоротшого шляху в отриманому графі робиться начебто за лінійний час. Для цього у вихідному графі алгоритм Дейкстри запускається як від початкової, так і від кінцевої вершини. При видаленні одного ребра найкоротший шлях у новому графі шукається з використанням дерев, отриманих для вихідного графа.
Модифікація алгоритму Йена
За рахунок того, що граф не орієнтований, при знаходженні кожного найкоротшого шляху в список кандидатів додається максимум три нових шляху.
Реалізація
Спробуємо реалізувати обидва алгоритму на мові C ++ з демонстрацією рішення в консольному додатку. Наші вирішувачі працюватимуть з матрицею ваг шляхів графа. У такій матриці кожна клітинка показує вагу ребра в орієнтованому графі. Алгоритм може також приймати на вхід граф, що має ребра з негативним вагою.
Для зручної роботи з матрицями ми будемо використовувати зручний клас для роботи з динамічними багатовимірними масивами. Розглянемо цей клас ближче.
клас array
Сам клас описується наступною конструкцією:
class c_array {private: int dimentions; // Nubmer Of Dimentions int * size; // Array Of Sizez-By-Dimention int * coords; // Array Of Coords-By-Dimention int length; // Total Length int * data; // Pointer to Data int id (); // Getting The ID public: // Initialization c_array (int dimentions, int size, ...); // Creating the Array c_array (int dimentions, int * size, int * data); // Creating the Array from Clone c_array (char * path); // Creating the Array from File ~ c_array (); // Cleaning Up Memory // Misc c_array_p clone (); // Clone the Array int save (char * path); // Save Data to File // Data int $ (int coords, ...); // Gets the Value int s (int value, int coords, ...); // Sets the Value int l (int dimention); // Get Lenght by Dimention};
Поля цього класу відповідають за дані нашого масиву. Ми вказуємо кількість вимірювань масиву, створюємо два масиви, що зберігають розмірності масиву по кожному з вимірів і координати запитуваної точки, загальну довжину масиву даних і посилання на сам масив.
Для цього класу передбачено три різних типи конструкторів. Основний варіант передбачає створення масиву за кількістю його вимірів і размерностям по кожному з вимірів. Другий варіант створює масив на базі вже існуючого, використовуючи посилання на його дані. Третій тип конструктора дозволяє завантажити масив з файлу.
Розглянемо докладніше головний архітектор:
c_array :: c_array (int dimentions, int size, ...) {this-> dimentions = dimentions; this-> length = size; this-> size = (int *) malloc (sizeof (int) * dimentions); this-> coords = (int *) malloc (sizeof (int) * dimentions); va_list argp; this-> size [0] = size; va_start (argp, size); for (int i = 1; i <dimentions; i ++) {this-> size [i] = va_arg (argp, int); this-> length * = this-> size [i]; } Va_end (argp); this-> data = (int *) malloc (sizeof (int) * this-> length); }
Робота даного конструктора елементарна. Ми заповнюємо поле кількості вимірювань по переданому першому параметру функції і виділяємо місце в пам'яті під два масиви - масив розмірності за вимірюваннями і масив координат точки. Далі, використовуючи макроси функцій з множинними параметрами, ми заповнюємо масив розмірності, підраховуючи також в циклі і загальну довжину масиву. Заповнимо масив розмірності, ми отримуємо повну довжину масиву, на основі якої виділяємо пам'ять під область даних масиву.
Для роботи з алгоритму Флойда нам буде потрібно клонування масивів. Для цього ми використовуємо просту функцію clone і конструктор клонування.
c_array_p c_array :: clone () {return new c_array (this-> dimentions, this-> size, this-> data); }
Конструктор клонування копіює дані з пам'яті за переданими в аргументі адресами.
c_array :: c_array (int dimentions, int * size, int * data) {this-> dimentions = dimentions; this-> length = 1; this-> size = (int *) malloc (sizeof (int) * dimentions); this-> coords = (int *) malloc (sizeof (int) * dimentions); for (int i = 0; i <dimentions; i ++) {this-> size [i] = size [i]; this-> length * = size [i]; } This-> data = (int *) malloc (sizeof (int) * this-> length); for (int i = 0; i <this-> length; i ++) {this-> data [i] = data [i]; }}
Для отримання і збереження даних використовуються дві функції - $ і s відповідно. Реалізація цих функцій в цілому дуже схожа - заповнюється масив координат з переданих аргументів, виходить ідентифікатор осередки масиву за даними координатами і в залежності від ідентифікатора функція повертає або встановлює значення осередку, або ж сповіщає про помилку переданих координат.
Функція отримання значення:
int c_array :: $ (int coords, ...) {va_list argp; this-> coords [0] = coords; va_start (argp, coords); for (int i = 1; i <dimentions; i ++) {this-> coords [i] = va_arg (argp, int); } Va_end (argp); int id = this-> id (); return (id! = -1)? this-> data [id]: -1; }
Функція установки значення осередки:
int c_array :: s (int value, int coords, ...) {va_list argp; this-> coords [0] = coords; va_start (argp, coords); for (int i = 1; i <dimentions; i ++) {this-> coords [i] = va_arg (argp, int); } Va_end (argp); int id = this-> id (); if (id! = -1) {this-> data [id] = value; return true; } Else return false; }
Обидві функції звертаються до функції id, яка перевіряє координати осередку і повертає її ідентифікатор.
int c_array :: id () {int num = 1; for (int i = 0; i <this-> dimentions; i ++) {if (this-> coords [i]> = this-> size [i]) {num = 0; break; }} If (num) {switch (this-> dimentions) {case 1: return this-> coords [0]; case 2: return this-> coords [0] + (this-> coords [1] * this-> size [0]); case 3: return this-> coords [0] + (this-> coords [2] * this-> size [1]) + (this-> coords [1] * (this-> size [0] * this- > size [1])); default: for (int i = 1; i <this-> dimentions; i ++) {int mult = 1; for (int j = 0; j <this-> dimentions - i; j ++) {mult * = this-> size [j]; } Num + = this-> coords [i] * mult; } Num + = this-> coords [0]; return num; }} Else return -1; }
Як ми бачимо, функція перш за все перевіряє передані в неї координати на відповідність размерностям масиву. Далі, в залежності від кількості вимірювань, ідентифікатор знаходиться за простими формулами, або ж використовується складна формула знайти код для багатовимірних масивів.
Додатково, ми реалізували функції збереження і завантаження масивів. Функція збереження дозволяє записати всі дані масиву в певний файл. З нього за допомогою конструктора третього типу можна завантажити дані в масив. Ознайомитися з ними можна в файлі array.cpp, їх реалізація елементарна і розглядати їх тут ми не будемо.
Клас floyd і реалізація алгоритму
Основна частина алгоритму реалізована в класі решателя c_floyd.
typedef class c_floyd {private: // Main Graph c_array_p graph; // Path Data c_array_p waypoints; int path_count; path_p paths; // Commmons int reset_floyd (); public: c_floyd (); ~ C_floyd (); // Graph Operations int graph_init (int vertexes); int graph_rand (); int graph_set (int a, int b, int weight); int graph_clear (int a, int b); int graph_load (char * path); int graph_save (char * path); int graph_print (); // Floyd Operations int floyd (int a, int b); path_p path (int id); int way_print (); int path_print (int id = -1); } C_floyd_t, * c_floyd_p;
Поля цього класу містять в собі основні дані, використовувані в алгоритмі. Перш за все, ми використовуємо масив, що описує граф - як не складно здогадатися, це поле graph.
Для опису знайдених шляхів використовується матриця точок шляху waypoints, що показує, в яку точку краще перейти, щоб потрапити з точки А в точку Б, кількість знайдених шляхів path_ count та, власне, масив знайдених шляхів paths.
Поточний стан системи, знайдені шляхи і точки, скидаються за допомогою функції reset_ floyd, яка очищає пам'ять від знайдених раніше шляхів. Ця функція викликається при будь-якій зміні графа, тому що в разі зміни графа шляху, як правило, стають неактуальними.
Для опису знайдених нами шляхів скористаємося структурою шлях.
typedef struct _path {int type; int length; int weight; int * points; } Path_t, * path_p;
Вона містить в собі тип шляху (оптимальний позначаємо як нуль, субоптимальний помічаємо одиницею), кількість точок в дорозі, його вага і посилання на масив точок шляху.
Конструктор і деструктор класу працюють тільки на виділення і звільнення пам'яті, розглядати з тут докладно не має сенсу.
Для роботи з самим графом ми використовуємо певний набір функцій, що дозволяють легко встановити всі його параметри.
Перш за все, граф створюється функцією graph_init.
int c_floyd :: graph_init (int vertexes) {if (this-> graph) {delete this-> graph; this-> graph = null; } This-> graph = new c_array (2, vertexes, vertexes); for (int i = 0; i <vertexes; i ++) {for (int j = 0; j <vertexes; j ++) {this-> graph-> s (0, i, j); }} This-> reset_floyd (); return true; }
В її завдання входить очищення попереднього графа, якщо такий є, виділення місця під новий об'єкт графа і заповнення його нулями.
Для роботи з уже існуючими графами ми можемо використовувати функції завантаження і збереження графів. Вони викликають безпосередньо функції завантаження і збереження масиву з класу графа, реалізацію їх можете розглянути в самому файлі.
У роботі нам може знадобитися редагування ваг ребер графа. Для цього використовуються дві функції: graph_set і graph_ clear. Функція graph_ set задає значення ваги ребра між вершинами A і B в передане значення. Функція graph_ clear прибирає ребро між цими точками, встановлюючи відстань між ними в нескінченність.
int c_floyd :: graph_set (int a, int b, int weight) {if (this-> graph) {this-> graph-> s (weight, a, b); this-> reset_floyd (); return true; } Else return false; } Int c_floyd :: graph_clear (int a, int b) {if (this-> graph) {this-> graph-> s (inf, a, b); this-> reset_floyd (); return true; } Else return false; }
У нашому випадку нескінченність, зрозуміло, не є істиною нескінченністю, ми використовуємо константу inf з досить великим значенням 0x0fffffff. Ми не використовуємо значення MAX_INT тому, що нам потрібно в деяких випадках складати значення ваг двох ребер нескінченної довжини, і в разі використання MAX_INT виникають помилки.
Щоб не ставити значення ваг ребер вручну, використовуємо функцію graph_rand.
int c_floyd :: graph_rand () {if (this-> graph) {int l = this-> graph-> l (0); for (int i = 0; i <l; i ++) {for (int j = 0; j <l; j ++) {if (i! = j) {int w = (rand ()% 2)? (Rand ()% 20 + 1): inf; this-> graph-> s (w, i, j); } Else this-> graph-> s (inf, i, j); }} This-> reset_floyd (); return true; } Else return false; }
Вона заповнює граф випадковими значеннями.
Додатково, є функція graph_ print, яка роздруковує граф в консолі. Вона виводить на екран матрицю ваг ребер графа.
Вирішувач - функція floyd
Основна логіка роботи алгоритму реалізована в функції floyd, яка отримує на вхід номера вершин A і B, і видає відповіддю кількість знайдених їй шляхів.
Починається наша функція тут ...
int c_floyd :: floyd (int a, int b) {if (! this-> graph) return false; this-> reset_floyd (); int l = this-> graph-> l (0); if (a <0 || a> l) return false; if (b <0 || b> l) return false;
Початок функції відповідає за мінімальну підготовку до роботи алгоритму. Ми очищаємо пам'ять і перевіряємо, чи входять необхідні точки в заданий нами діапазон розмірів графа.
this-> waypoints = new c_array (2, l, l); for (int i = 0; i <l; i ++) {for (int j = 0; j <l; j ++) {this-> waypoints-> s (j, i, j); }}
Перед запуском алгоритму ми повинні підготувати матрицю точок шляху, яку ми заповнюємо для початку кінцевими точками маршруту.
c_array_p old_step, new_step, temp_step; old_step = new c_array (2, l, l); new_step = this-> graph-> clone ();
Для роботи нам будуть потрібні дві матриці, які використовуються при знаходженні ваг найкоротших шляхів. Першу ми клонуємо з графа, другу створюємо аналогічного розміру, але не заповнюючи даними.
Алгорімт працює в трьох вкладених циклах, як і описано вище. Перед кожним із циклів ми міняємо матриці місцями, і продовжуємо заповнення.
Щоразу елемент матриці встановлюється в значення найкоротшого шляху з даної точки в потрібну точку. При цьому, якщо нове значення краще, ніж поточний, поточне значення замінюється. У цьому випадку також змінюється матриця точок шляху, см. # 1.
for (int k = 0; k <l; k ++) {// Exchanging Step Matrix temp_step = old_step; old_step = new_step; new_step = temp_step; // Floyding for (int i = 0; i <l; i ++) {for (int j = 0; j <l; j ++) {int w = old_step -> $ (i, k) + old_step -> $ (k , j); if (w> = inf) w = inf; if (w <old_step -> $ (i, j)) {// WayPoint Setting int nk = (i! = k)? this-> waypoints -> $ (i, k): k; this-> waypoints-> s (nk, i, j); } Else w = old_step -> $ (i, j); new_step-> s (w, i, j); }}}
Після проходу алгоритму ми можемо сміливо видаляти використані нами матриці - вони більш не потрібні.
delete old_step; delete new_step;
Наступним найважливішим кроком алгоритму є власне побудова шляху. Для цього завдання ми використовуємо створену нами матрицю шляхових точок. Як ми бачимо, матриця шляхових точок дозволяє нам легко відкласти шлях з будь-якої точки в будь-яку точку.
Звернемо увагу, що при побудові шляху ми не використовуємо нескінченний цикл. Причина проста. Ми можемо гарантовано стверджувати, що будь-який оптимальний і субоптимальний шлях по графу з однієї точки в іншу завжди буде довжиною менше або дорівнює кількості вершин у графі. Довести це нескладно. Якщо припустити, що довжина шляху перевищує кількість точок, значить як мінімум одну з точок шляху ми відвідуємо більше одного разу. Це означає, що з однієї точки ми проробляємо два шляхи, один з яких є петлею, і повертає нас назад в цю ж точку, відповідно може бути виключений як зайвий елемент шляху.
path_t best_path; best_path.type = -1; best_path.weight = 0; best_path.points = (int *) malloc (sizeof (int) * l); for (int p = 0; p <l; p ++) {if (p) {best_path.points [p] = this-> waypoints -> $ (best_path.points [p-1], b); best_path.weight + = this-> graph -> $ (best_path.points [p-1], best_path.points [p]); if (p> 1) {// Cathing Bad Path and Send if (best_path.points [p] == best_path.points [p-2]) p = l-1; }} Else {best_path.points [0] = a; } // Finishing? if (best_path.points [p] == b) {best_path.type = 1; best_path.length = p + 1; break; }}
У разі якщо шлях приводить нас в точку B, ми встановлюємо тип шляху в одиницю (оптимальний шлях). В іншому випадку, якщо шлях за кінцеве число кроків, менше кількості вершин у графі, що не привів нас в точку B, значить, в графі є цикли, які даний алгоритм і не виконує жодних.
Далі, ми знаходимо субоптимальних шляху по ідеї алгоритму Йена. Ми розглянемо певне число варіантів шляху, намагаючись на кожному з кроків шляху вибрати не оптимальну точку, а другу по оптимальності. Таким чином, ми можемо максимум розглянути стільки шляхів, скільки точок є в оптимальному шляху.
if (best_path.type! = -1 && best_path.length> 2) {int i_path_count = 0; path_p i_paths = (path_p) malloc (sizeof (path_t) * (best_path.length - 2)); for (int i = 0; i <(best_path.length - 2); i ++) {i_paths [i] .type = -1; i_paths [i] .length = 0; i_paths [i] .weight = 0; i_paths [i] .points = null; }
Алгоритм побудова субоптимальних Шляхів відрізняється від алгоритму побудова оптимального шляху в одному з кроків, див. # 2. На цьом етапі ми перевіряємо, Який Із Шляхів (за номером) ми аналізуємо, и чи збігається номер шляху з номером поточної точки. Если номер шляху НЕ збігається, то побудова ведеться як в попередня випадки. В ІНШОМУ випадки вместо оптімальної точки шляху з матриці Шляхова точок ми будемо використовуват іншу точку, шлях по Якій буде відрізнятіся від оптимального. Якщо такої точки не існує, то перейдемо до наступного субоптимального шляху, так як субоптимального шляху, що відрізняється від оптимального цією точкою, не існує.
for (int k = 1; k <best_path.length - 1; k ++) {if (i_paths [i_path_count] .points) free (i_paths [i_path_count] .points); i_paths [i_path_count] .points = (int *) malloc (sizeof (int) * l); for (int p = 0; p <l; p ++) {if (p == k) {int n2p = (p> 1)? i_paths [i_path_count] .points [p-2]: 1; int next_id = -1; int next_wg = inf; // Searching Next Way Poing not Best but Yet Good =) for (int i = 0; i <l; i ++) {// i not this point, not previous point and not best point if (i! = I_paths [i_path_count] .points [p-1] & i! = n2p & i! = this-> waypoints -> $ (i_paths [i_path_count] .points [p-1], b)) {if (this-> graph -> $ ( i_paths [i_path_count] .points [p-1], i) <next_wg) {next_id = i; next_wg = this-> graph -> $ (i_paths [i_path_count] .points [p-1], i); }}} If (next_id! = -1) {i_paths [i_path_count] .points [p] = next_id; i_paths [i_path_count] .weight + = this-> graph -> $ (i_paths [i_path_count] .points [p-1], next_id); } Else p = l - 1; // Finishing, path is bad ...} else if (p) {// Simply Adding Next Way Point i_paths [i_path_count] .points [p] = this-> waypoints -> $ (i_paths [i_path_count] .points [p -1], b); i_paths [i_path_count] .weight + = this-> graph -> $ (i_paths [i_path_count] .points [p-1], i_paths [i_path_count] .points [p]); if (p> 1) {// Cathing Bad Path and Send if (i_paths [i_path_count] .points [p] == i_paths [i_path_count] .points [p-2]) p = l-1; }} Else {// Starting i_paths [i_path_count] .points [0] = a; } // Finishing? if (i_paths [i_path_count] .points [p] == b) {i_paths [i_path_count] .type = 0; i_paths [i_path_count] .length = p + 1; i_path_count + = 1; break; } // Bad Path Got? if (p == l-1) {free (i_paths [i_path_count] .points); i_paths [i_path_count] .points = null; }}}
Після знаходження всіх шляхів, ми можемо перенести їх в пам'ять рішення. Ми окремо виділяємо місце під остаточне рішення з метою економії пам'яті.
// Copying Paths to Result Array this-> paths = (path_p) malloc (sizeof (path_t) * (i_path_count + 1)); // Best Path this-> paths [0] .type = 1; this-> paths [0] .length = best_path.length; this-> paths [0] .weight = best_path.weight; this-> paths [0] .points = (int *) malloc (sizeof (int) * best_path.length); for (int p = 0; p <best_path.length; p ++) {this-> paths [0] .points [p] = best_path.points [p]; } // Sub Paths for (int i = 0; i <i_path_count; i ++) {this-> paths [i + 1] .type = i_paths [i] .type; this-> paths [i + 1] .length = i_paths [i] .length; this-> paths [i + 1] .weight = i_paths [i] .weight; this-> paths [i + 1] .points = (int *) malloc (sizeof (int) * i_paths [i] .length); for (int p = 0; p <best_path.length; p ++) {this-> paths [i + 1] .points [p] = i_paths [i] .points [p]; } Free (i_paths [i] .points); } Free (i_paths); this-> path_count = i_path_count + 1; } Else if (best_path.type! = -1) {this-> paths = (path_p) malloc (sizeof (path_t)); // Best Path this-> paths [0] .type = 1; this-> paths [0] .length = best_path.length; this-> paths [0] .weight = best_path.weight; this-> paths [0] .points = (int *) malloc (sizeof (int) * best_path.length); for (int p = 0; p <best_path.length; p ++) {this-> paths [0] .points [p] = best_path.points [p]; } This-> path_count = 1; }
Після копіювання шляхів в пам'ять рішення, тимчасова пам'ять очищається і функція повертає кількість знайдених їй шляхів.
free (best_path.points); return this-> path_count; }
Цим функція побудови шляху закінчується. На виході користувач має кількість шляхів. Таким чином, використовуючи функцію path, передавши їй як параметр номер шляху, ми отримаємо інформацію про кожен конкретний шляху. При цьому нульовий номер завжди має оптимальний шлях.
Функція path повертає посилання на структуру шляху, що міститься в вирішувача.
path_p c_floyd :: path (int id) {if (this-> path_count == 0 || id <0 || id> this-> path_count) {return false; } Else return & this-> paths [id]; }
Звернемо увагу, що в разі скидання решателя (при будь-якої операції з графами або запуску нового циклу решателя) дана посилання стає неактуальною, оскільки скидається і вся пам'ять рішень. Тому, в разі використання даного рішення багаторазово, після його отримання варто скопіювати його в окрему область пам'яті.
Клас floyd також містить в собі ряд функцій, які ми використовуємо для демонстрації решателя. Ці функції відповідають за роздруківку шляху, графа і матриці шляхових точок, їх можна вивчити безпосередньо в коді класу, розглядати тут їх не має сенсу через їх очевидності і простоти реалізації.
Демонстрація роботи алгоритму
Для простої демонстрації роботи алгоритму напишемо невелику консольний додаток. Воно виводить нам просте текстове меню, що запитує у користувача вибір дії. Залежно від обраного дії безпосередньо викликається функція класу floyd із запитаними у користувача параметрами.
Можливі такі варіанти дій:
- Створити граф певного розміру з випадковим вагою ребер.
- Відобразити матрицю ваг в консолі.
- Відредагувати вага ребра в даній точці.
- Запустити вирішувач по алгоритмам Флойда і Йена.
- Показати шляху, знайдені в пункті 4.
- Показати матрицю шляхових точок, використовувану в пункті 4.
- Зберегти граф в файл graph.data.
- Завантажити раніше збережений файл з graph.data.
- Вийти з програми.
Ця програма може використовуватися для демонстрації роботи бібліотеки функцій решателя за алгоритмом Флойда. З невеликою доопрацюванням ця бібліотека може бути використана в реальних проектах.
Висновок
Розглянуті алгоритми можуть легко застосовуватися для знаходження оптимального і субоптимальних шляхів в графі. Використовувані нами класи легко можуть впроваджуватися в існуючі програмні продукти на мові C ++ і використовуватися для вирішення завдань в реальному часі. Реалізації алгоритму Флойда і Ієна можуть, також, використовуватися окремо, їх код легко вичленяються із загального контексту.
ПОСИЛАННЯ
Реалізовані тут алгоритми описані в наступних статтях:
- Wikipedia - http://ru.wikipedia.org/wiki/Алгоритм_Флойда_-_Уоршелла
- CurtisWiki - http://lib.custis.ru/index.php/Алгоритм_Флойда-Уоршолла
- http://khpi-iip.mipk.kharkiv.edu/library/datastr/book_sod/kgsu/din_0124.html
- Алгоритм Йена - http://algolist.manual.ru/maths/graphs/shortpath/yen.php
За цими посиланнями можна знайти більш детальний опис алгоритму, а також розглянути його реалізації на різних мовах програмування.
Тексти програм до цієї статті Ви можете завантажити тут:
- исходник - http://www.av13.ru/wp-content/uploads/2009/12/floyd-src.zip
- Реалізація - http://www.av13.ru/wp-content/uploads/2009/12/floyd-exe.zip
- звіт - http://www.av13.ru/wp-content/uploads/2009/12/floyd-rtfm.zip
Створено в Microsoft Visual Studio 2008, ліцензія кафедри АСУ Фет МДУ ім. Н.П.Огарёва.
Автор
Автором даної статті є Антон «AlterVision» Резніченко. Публікація статті цілком або частково можлива тільки з дозволу автора.
9 грудня 2009 р 18:50
Int c_floyd :: graph_rand () {if (this-> graph) {int l = this-> graph-> l (0); for (int i = 0; i <l; i ++) {for (int j = 0; j <l; j ++) {if (i! = j) {int w = (rand ()% 2)?Points [0] = a; } // Finishing?
Points = (int *) malloc (sizeof (int) * l); for (int p = 0; p <l; p ++) {if (p == k) {int n2p = (p> 1)?
Points [0] = a; } // Finishing?
Length = p + 1; i_path_count + = 1; break; } // Bad Path Got?