Аналіз конкурентів.: Аналіз сайту.: Блог SEO програміста
- Трохи теорії про застосовувані терміни:
- Статистична міра тексту - TF-IDF
- Для чого потрібно знати вагу слова
- Закони Ціпфа AKA Зіпфа
- завдання копірайтер
- Міркування на тему тирінга контенту
- Алгоритм аналізу текстів конкурентів.
Прийшла пора застосувати знання, отримані на занятті про написання контенту, на практиці.
Щоб полегшити собі життя і своїм конкурентам виберу дуже животрепетну тему: навчальний запит :)
Трохи теорії про застосовувані терміни:
Без вкуріванія в цю частину все інше читати можливо безглуздо ...
Статистична міра тексту - TF-IDF
TF виражає відношення входжень окремо взятого слова до загальної кількості слів в окремо взятому документі - частота слова
DF - частота документа - виражається відношенням загального числа документів з конкретним ключовим словом до числа документів взагалі. В даному випадку число документів взагалі - це загальна кількість проіндексованих пошуковою системою сторінок.
IDF - це DF догори ногами
Міра TF-IDF дозволяє оцінити вагу ключового слова у всіх проіндексованих пошуковою системою сторінках.
Формули (поцупив з вікіпедії):
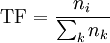 , Де ni - число входжень слова в документ, сума в знаменнику - загальне число слів в документі
, Де ni - число входжень слова в документ, сума в знаменнику - загальне число слів в документі
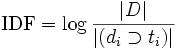 , Де | D | - кількість документів, а хрень в знаменнику символізує кількість документів, в яких зустрічається шукане ключове слово
, Де | D | - кількість документів, а хрень в знаменнику символізує кількість документів, в яких зустрічається шукане ключове слово
Але існує досить більша кількість методик розрахунку IDF. Найпростіший спосіб - це розділити кількість документів, в яких зустрічається ключове слово на число документів у пошуковій системі.
Для розрахунку остаточного ваги слова небхідно розділити TF на DF або TF помножити на IDF.
Для чого потрібно знати вагу слова
Основне призначення - це що-б наші ключові слова були найвагомішими на яку просуває сторінці сайту. Побічний ефект - можна побачити "несумісність" ключових слів для просування на одній сторінці сайту через кардинально різняться їх ваг.
Наприклад слів труну важить 100 у.о., а слово тапок - всього 5. І з цього випливає, що якщо почати рухати на одній сторінці труну з білими капцями, то текст може тупо вибиватися з закономірностей Ціпфа і буде розпізнано пошуковою системою як неприродний з витікаючими з цього фільтрами. Плюс вага білих тапок може розчинитися в вазі труни.
Закони Ціпфа AKA Зіпфа
 Що таке закон Ціпфа - це (далі вікіпедія):
Що таке закон Ціпфа - це (далі вікіпедія):
емпіричне правило розподілу частоти слів природної мови: якщо все слова мови (або просто досить довгого тексту) впорядкувати по спадаючій частоти їх використання, то частота n-го слова в такому списку опиниться приблизно обернено пропорційній його порядковому номеру n (так званому ранку цього слова) . Наприклад друге за використовуваного слово зустрічається приблизно в два рази рідше, ніж перше, третє - в три рази рідше, ніж перше, і т. Д.
Основне знання з цього чуда: існує величина C (ранк-частота), яка більш-менш постійна для тексту на певному мовою. Для літературної російської - це 0.06 ... 0.07.
Для розрахунку C застосовується наступна формула: C = (Частота входження слова * Ранг частоти) / Число слів

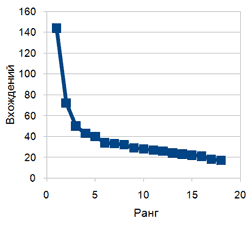
На зображення порахована по закону Зіпфа - ранк-частота для топ ключових слів для топ-10 Яндекса по темі "міжкімнатні двері". Як видно з графіка в країні повний бардак.
Ціпфа також встановив, що частота і кількість слів, що входять в текст з однією частотою, залежні між собою і тільки злегка відрізняються для різних мов. Виражається поняттям кількість-частота = кількість входжень слова / частота слова.
Бажаючі можуть спробувати осягнути знання далі , А я спробую проаналізувати себе і конкурентів за навчальним запитом.
Насамперед питаю в Яндексі навчальний запит і на ліпшу топ-4 (інші безглузді) нацьковували будь семантичний аналізатор тексту. Для реальному житті краще використовувати сайти в топ 20. Не забуваємо виставити потрібний регіон в пошуковику, якщо він це вміє.
Побіжний аналіз показав, що перші чотири сторінки в топі Яндекс складаються з 662, 1236, 594 і 995 слів і містять стоп-слів: 197, 427, 249 і 268. Тобто ідеальна довжина тексту повинна бути десь в районі 900 слів . Не варто забувати викинути з аналізу все, що сидить під <noindex>. Для Яндекса найпростіший спосіб - це взяти сторінку з кешу, але вона може бути вже злегка застарілою.
Ранк-частота для сторінок сайтів-конкурентів за навчальним запитом вийшла різна: від 0.003 до 0.035, що вивалюється з рекомендованого для російської мови.
Тепер пройдуся власне за словами: для аналізу буду брати слова з частотою в районі одиниці і вище, тому що далі йде відверта маячня не по темі. Попутно накладаю обмеження у вигляді здорового глузду, бо тема досить загадкова.
Аналізую текст, прийшов до висновку, що крім всіх варіантів написання слів навчальний запит в тексті повинні бути присутніми слова сайт, пошук / пошуковий, seo, просування, навчання, курс та лекція. Частота основного запиту від 5 до 9%.
Залишилося сісти і написати текст, використовуючи рекомендації вище. А потім потиху стежити за конкурентами і вносити корективи в міру зміни позицій в топі.
Сайти-конкуренти розділилися на дві купки - хтось рухає головну, а хто-то окрему сторінку сайту. Тобто і для мене можна використовувати будь-яку з двох стратегій.
Тепер за структурою сторінки. У частині це головна блогу зі стрічкою, в якій в заголовках розмазаний навчальний запит, а для інших це тематична сторінка зі статтею. У більшості присутні зображення.
Написання тексту швидше за все довірю біржі копірайту, тому що схоже що їх доведеться використовуватися в процесі навчання.
завдання копірайтер
Написати структурований текст довжиною близько 900 слів на тему навчальний запит, використавши такі слова: сайт, пошук / пошуковий, seo, просування, навчання, курс та лекція.
Словосполучення "навчальний запит" у всіх варіаціях має вживатися з частотою близько 7%.
Залишити місце в тексті для двох-трьох зображень.
Міркування на тему тирінга контенту
Вищеописаний приклад кілька невдалий через його поки малої поширеності. Ближче до кінця занять на курсах навчальний запит повинен бути в топ-40.
Алгоритм аналізу текстів конкурентів.
- Беремо топ-20 по пошуковій системі. Для рідної Білорусі це може бути топ 10.
- Проганяємо через будь-який аналізатор контенту. рекомендують істіо . Не забуваємо викинути те, що сидить в noindex.
- Никаться собі наступні дані: довжина без пробілів, кількість слів і топ-20 слів без стоп-слів (за бажанням топ слів можна розширити або зменшити)
- Вважаємо середню довжину тексту, викидаючи те, що дуже відверто відрізняється від інших. Для цієї справи навіть існує спеціальні формули, які я вивчав ще в архітектурно-будівельному технікумі на якомусь предметі, пов'язаному зі статистикою.
На виході має середню довжину контенту, яка нам потрібна. - Слідом аналізуємо кількість прямих входжень кейвордов, тупо заходячи на сайти і вважаючи їх руками.
На виході має число точних входжень ключових слів / фраз. - Вважаємо кількість словоформ шляхом вирахування з даних істіо точних входжень, отриманих кроком вище
- Потім отримуємо наше семантичне ядро. Для цього дані з істіо по всім сайтам скармливаем знову-ж в істіо, відкидаємо ті слова, що рідко зустрічаються і отримуємо власне ядро.
- Усе. Телемаркет. Залишилося написати текст самому або дати завдання копірайтер на базі наявної довжини тексту, кількості прямих входжень і семантичного ядра.
Важливо. Дивіться на структуру аналізованих сайтів. У моєму домашньому завданні по темі чітко поділялися дві конкуруючі структури: каталог і текст з картинками. Можливо доведеться вибрати один з варіантів структурування тексту або застосувати обидва варіанти, але на різних сторінках.
PS: Стир з форуму Artox і злегка доопрацьовано.